
회사에서 운영하는 서비스 중 고객사(병원)에서 매일 회진을 시작하기 전 의사가 회진 일정을 선택 후 환자에게 알림 메시지를 전송하는 서비스가 있다. 고객사에서는 이 서비스를 의사들이 해당 서비스를 잘 사용하고 있는지 확인하기 위해 통계를 보여주는 서비스도 만들어 달라고 요청했었는데, 이번에 기능 추가 요구사항이 생겨 내가 업무를 담당하게 되었다.
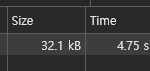
단순히 통계 자료의 컬럼 몇 개를 추가해달라는 요구사항이라 쉬울 거라 예상했지만, 실제로 작업을 시작하면서 놀란 부분이 있다. 조회 조건에 따라 다르지만 가장 많이 조회하는 한 달 통계를 조회하면 API 응답 시간이 4.75초나 걸리고 있었다. 실제로 통계 자료를 자주 조회하는 것도 아니고 불편하다는 CS 도 없었지만 흔치 않은 성능 개선 기회라 놓칠 수 없었다!
이전에도 운영 중인 서비스에 장애가 계속 발생해서 원인을 찾고 해결하겠다는 의사를 비쳤지만, 회사에선 내게 기존 시스템의 코드를 수정하기보다 새로운 프로젝트에 집중해 줬으면 좋겠다는 이야기를 한 적이 있었다. 아무래도 회사 입장에서 수익을 발생시키는 건 새로운 프로젝트를 꾸준히 만드는 것이기 때문에 충분히 동의 하였다. 하지만 마음속으로는 불편함을 갖고 있었는데, 이번 이슈는 추가 기능 작업을 하는 김에 성능을 개선하여 업데이트할 수 있을 것 같아 같이 작업을 하였다.

개선 과정
사내 백엔드 개발 환경
일단 앞으로 적을 내용을 보며 의아해할 분들이 있을 수도 있겠다는 생각이 들어 현재 회사의 상황에 대해 간략히 적어보고자 한다.
현재 회사는 국내 대형 병원 중 한 곳의 모바일 애플리케이션 개발을 전담하고 있다. 병원에선 개인정보를 위해 DB 에 따로 데이터를 저장하지 못하게 하고 필요한 정보는 전문 통신을 통해 제공하고 있었다. 그러다 보니 백엔드 개발이라는 개념 자체가 없이 모바일 애플리케이션만 개발하고 있다. (이 문제를 해결하고자 하는 의지가 강한 것도 백엔드 직무를 희망하는 나로서 3년이 되는 경력 동안 유일하게 본 백엔드 업무이기 때문이다)
백엔드 개발을 한 프로젝트는 현재 문제가 있는 시스템 하나였다. 때문에 팀원들은 비교적 백엔드 개발엔 이해도가 적을 수 있다.
백엔드 프레임워크도 회사에서 개발한 (express.js 를 이용한) 자체 프레임워크를 사용하기 때문에 트랜잭션, 레이어드 아키텍쳐, 의존 주입 등 기능이 없이 컨트롤러에 비지니스 로직이 절차 지향으로 담겨있기 때문에 보는 입장에서 어색할 수 있다.
또한 고객사에선 POST 요청만 강제하기 때문에 http 캐시는 사용할 수 없었다.
DB 테이블
통계에 필요한 테이블에 대한 간략한 내용이다.
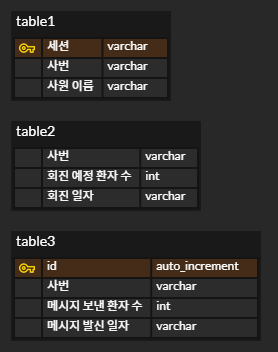
- table1 - 사용자가 로그인할 때 사용하는 키를 담아둔다. 사원 이름은 해당 테이블에서만 조회가 가능하다.
- table2 - 의사들의 회진 예정에 대한 정보는 해당 테이블에서 조회가 가능하다.
- table3 - 의사들이 환자들에게 메시지를 전송하면 몇 명에게 전송했는지 기록하는 테이블이다. 회진 예정된 환자가 있어도 전송하지 않을 수도, 여러 번 전송할 수도 있다.
중복된 데이터가 있고 PK 가 없는 테이블도 있다… index 는 당연히 기대할 수 없다. 정규화를 거쳐 테이블 간 연관관계를 만들면 조금 더 깔끔한 테이블이 만들어질 것 같다. 하지만 함부로 테이블을 수정할 수 없는 환경이라 현재 주어진 상황에서 해결해야 한다.
필요한 기능
개발되어 있던 기존 기능과 추가로 필요한 정보는 다음과 같다.
- 의사 개별 통계
- 사번
- 이름
- 진료과
- 발송율 - 기간 내 메시지를 보내야 하는 환자가 있는 날 중 실제 메시지를 보낸 일의 비율
- 발송 건수 - 기간 내 환자에게 실제 총발송한 횟수
- 발송 일수(추가) - 기간 내 환자에게 실제 발송한 일수의 합
- 회진 예정 일수(추가) - 기간 내 메시지 보내야 하는 환자가 있는 일수의 합
- 진료과별 통계
- 진료과
- 발송율 - 진료과 별 기간 내 메시지를 보내야 하는 환자가 있는 의사 중 실제 메시지를 보낸 일의 비율
- 발송 건수 - 진료과 별 기간 내 환자에게 실제 총발송한 횟수
- 발송 의사 수(추가) - 진료과 별 기간 내 환자에게 실제 발송한 의사의 합
- 회진 예정 의사 수(추가) - 진료과 별 기간 내 메시지를 보내야 하는 환자가 있는 의사의 합
병목 지점
API 응답 속도를 늦췄던 원인은 의사 개별 통계의 기존 통계 자료를 조회하는 쿼리였다.
SELECT
t2.사번,
t2.부서명,
TRUNCATE(SUM(CASE WHEN t3.환자수 <> 0 THEN 1 ELSE 0 END) / COUNT(*) * 100, 1) AS 발송율,
COALESCE(SUM(t3.환자수), 0) as 발송 건수
FROM table2 as t2
LEFT JOIN table3 as t3
ON t2.사번 = t3.사번
AND DATE_FORMAT(t2.회진 일자, '%Y-%m-%d') = DATE_FORMAT(t3.발신 일자, '%Y-%m-%d')
WHERE ...해당 쿼리만 조회하는데 3.5초가 걸렸다.
한방 쿼리를 사용하기 위해 table2 와 table3 가 조인이 됐는데 이게 문제였다.
table2 와 table3 는 각각 데이터가 많은 편이었는데 8월 한 달간 쌓인 데이터는
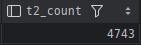
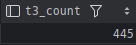
각각 4743, 445건으로 많았는데, 두 테이블을 조인하면서 문제가 발생할 것으로 예상했다.
내가 예상한 조인에서의 문제는
- date 컬럼을 사용하지 않아 날짜 함수를 사용하면서 풀 테이블 스캔 발생
- 데이터가 많은 두 테이블을 전체 탐색
이었다.
문제 해결 1 - 조인에서 날짜 함수 제거
일단 조인에서 날짜 비교 구문을 제거했다.


미약하지만 0.5초 개선 됐다….
문제 해결 2 - 사번 컬럼 인덱스 추가
이번엔 인덱스를 추가하는 방법으로 개선이 가능한지 확인하고자 했다. 실제 운영 환경에선 사용하진 못하지만, 로컬에서라도 인덱스를 추가해서 성능 차이가 발생하는지 비교해 봤다.
table2 와 table3의 사번 컬럼에 각각 인덱스를 걸어 주었다.
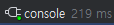
엄청난 성능 향상이 이뤄졌다! 개인적으론 아직 느리다고 생각하지만 기존 발생한 소요 시간에 비교하면 엄청난 개선이었다.
아쉬운 건 운영 환경의 테이블을 수정하는 건 불가하다 하셔서 인덱스를 추가할 순 없었다. 거기다 이번에 추가해야 하는 컬럼은 발송율 컬럼에 사용될 분자, 분모 값이기 때문에 한방 쿼리를 사용하면 같은 값을 두 번씩 연산하는 셈이 된다.
그렇기 때문에 이번엔 DB 쿼리가 아닌 애플리케이션 레벨에서 문제를 해결하고자 했다.
문제 해결 3 - 각 테이블 조회 후 애플리케이션에서 매핑
일단 간단한 조인과 요청받은 조회 파라미터를 포함한 쿼리를 이용해 각 테이블을 조회하기로 했다.
select t2.사번, t1.사원 이름, t2.부서명, t2.환자 수, t2.회진 일자
from table2 as t2
inner join table1 as t1
on t2.사번 = t1.사번select t3.사번, t3.환자 수, t3.발신 일자
from table3 as t3
inner join table1 as t1
on t3.사번 = t1.사번기존 쿼리는 사원 이름을 위한 table1 쿼리를 전체 조회 후 매핑시켜주고 있었다.
이때도 불필요한 table1 전체 탐색이 이뤄지기 때문에 해당 문제를 개선하기 위해 table2 테이블을 조회할 때 조인을 이용해 사원 이름을 추가했다.
table3 테이블을 조회할 때 table1 과 조인한 이유는 클라이언트에서 조회 조건으로 사원 이름을 추가할 수 있기 때문에 where 절을 위해 조인을 해두었다.
이 개선 방법은 매우 간단하기 때문에 딱히 기술할 내용은 없지만, 의미 있는 시도를 한 건 class를 이용한 점이다.
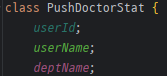
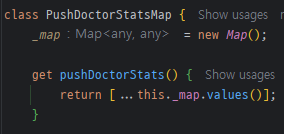
클래스를 사용하여 entity를 만들었고 해당 객체를 담을 일급 컬렉션을 사용하였다.

reduce 같은 배열 함수를 이용해 일급 컬렉션에 통계 자료를 담는 방법을 사용하였다.
자세한 코드는 공개할 순 없지만 일급 컬렉션도 회사에선 처음 사용했고 class를 이용해 엔티티 개념을 사용한 것도 이번이 첫 시도였다. 개인적인 공부나 프로젝트에선 항상 강타입 언어만 사용했던 터라 class를 이용했다 하더라도 심적으로 불편한 부분이 많지만, 어찌 됐든 기존 회사 개발 방법에서 확장 시켜준 점이 이번 개선 경험에서 가장 뿌듯한 부분이다.
개선 결과
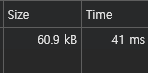
어찌 됐든 결과는 41ms로 4.7초 이상 빨라졌다. 심지어 인덱스를 추가했을 때보다도 훨씬 빠른 수치이다.
기존 api 는 col1, col2 같은 의미 없는 key로 응답을 보내주고 있어 좀 더 의미가 명확한 이름을 key로 변경했더니 api 응답 사이즈는 조금 더 커졌다. 응답 크기가 커져도 속도가 훨씬 빨라졌으니 의미 있는 개선이라고 생각한다.